AI
A new open-source multimodal AI called Ovis2 is turning heads by matching—and sometimes surpassing—the capabilities of models ten times its size. Developed by AIDC-AI, this 34-billion parameter system builds on last year's Ovis1.6 architecture with structural improvements that better align visual and textual understanding, while adding video processing and enhanced optical character recognition (OCR) across multiple languages.
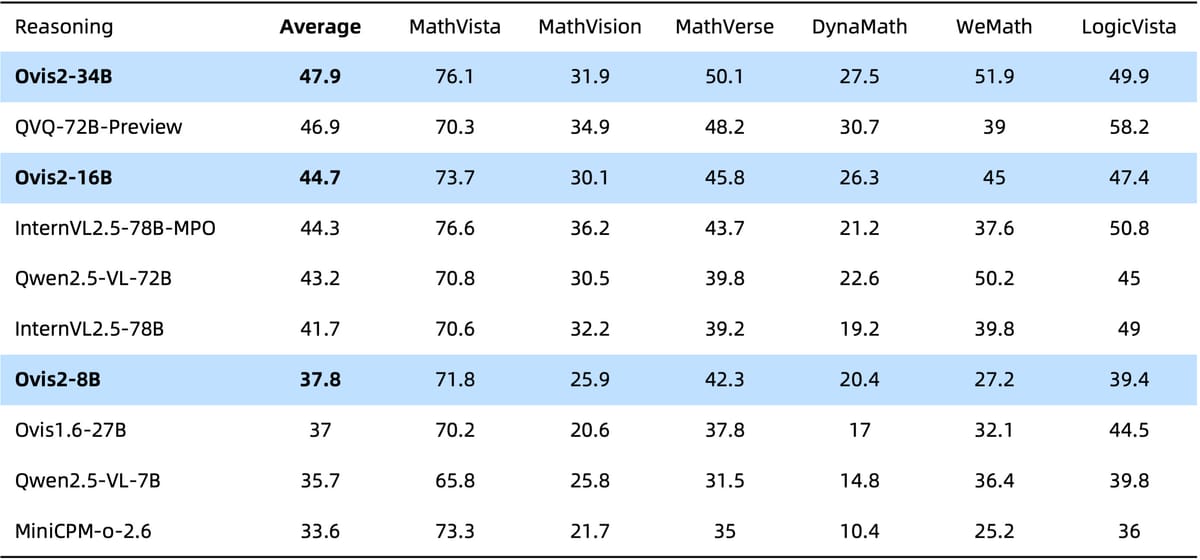
Early benchmarks shared on Hugging Face show the model outperforming larger competitors like Qwen-VL-Plus in specialized tasks. On the MathVista test of visual math reasoning, Ovis2-34B scored 76.1% accuracy—nearly 8 points higher than LLaVA-OV-72B. It also aced document understanding challenges with 89.4% on OCRBench, suggesting strong potential for real-world applications like form processing and chart analysis.
Small package, big upgrades
What makes Ovis2 notable isn't just its capabilities, but how it achieves them. The team employed what they call "capability density optimization"—training techniques that squeeze more performance from smaller architectures. While giants like GPT-4V and Gemini Ultra dominate headlines, this approach could lower the hardware barrier for running advanced vision-language models locally.
Key improvements include:
- Frame-by-frame video analysis: Unlike many models that treat video as a series of still images, Ovis2 processes temporal relationships between frames using a novel tokenization method. Early tests show 75.97% accuracy on the TempCompass temporal reasoning benchmark.
- Multilingual OCR: The model now extracts text from images in Chinese, Japanese, and Korean with comparable accuracy to its English capabilities—a boon for global document processing.
- Structured data parsing: Improved interpretation of tables, charts, and forms through what developers describe as "visual syntax recognition" in their arXiv paper.
Benchmark battlegrounds
In the increasingly crowded field of multimodal AI, Ovis2 carves out a niche through balanced performance. While it doesn't top every category, the model shows particular strength in scenarios requiring combined visual and logical reasoning:
- MathVista: 76.1% (testmini) vs. Qwen-VL-Plus' 56.6%
- MMVet: 77.1% accuracy in detailed visual question answering
- HallusionBench: 58.8% on hallucination detection, suggesting lower rates of "making things up" compared to earlier versions
The full benchmark results reveal an interesting pattern—Ovis2 frequently outperforms larger models on tasks requiring precise visual interpretation, while lagging slightly in broader knowledge-based queries. This aligns with the team's focus on structural alignment between visual and textual embeddings, a technique that appears to reduce "cross-modal confusion" during processing.
{kind=link}
From theory to terminal
For developers interested in testing Ovis2, the model comes in six sizes from 1B to 34B parameters, all available via Hugging Face. The recommended 34B version requires significant GPU memory but can run on consumer hardware using quantization techniques. AIDC provides detailed installation instructions supporting both single-image and video inputs.
One community request gaining traction is Ollama integration, which would enable local OCR workflows on Macs and PCs. "Being able to run this level of document understanding offline could be game-changing for privacy-focused applications," commented a developer in the Ollama GitHub discussion.
The compliance tightrope
Like all large language models, Ovis2 comes with caveats. The technical paper acknowledges using "compliance-checking algorithms" during training to filter problematic content, but warns that "copyright issues or improper content risks remain" due to the model's broad training data. This echoes challenges faced by other open-source projects like LLaVA and Mistral in balancing capability with safety.
As multimodal models increasingly handle real-world visual data—from medical imaging to street view photos—the Ovis team's approach of structural alignment offers an intriguing path forward. By treating visual elements more like language tokens, they've created a model that reasons with images rather than just recognizing them. Whether this architectural shift becomes the new standard may depend on how well it scales to even larger parameter counts—and how the open-source community builds upon this foundation.