AI
Edited Feb 16, 2025
A new open-source language model is turning heads not for its size, but for what it achieves without the computational heft of its predecessors. DeepScaleR-1.5B-Preview, a 1.5-billion-parameter model developed by the Agentica Project, claims to outperform OpenAI’s proprietary O1-Preview in specialized reasoning tasks—all while costing less to train than some startups spend on office snacks.
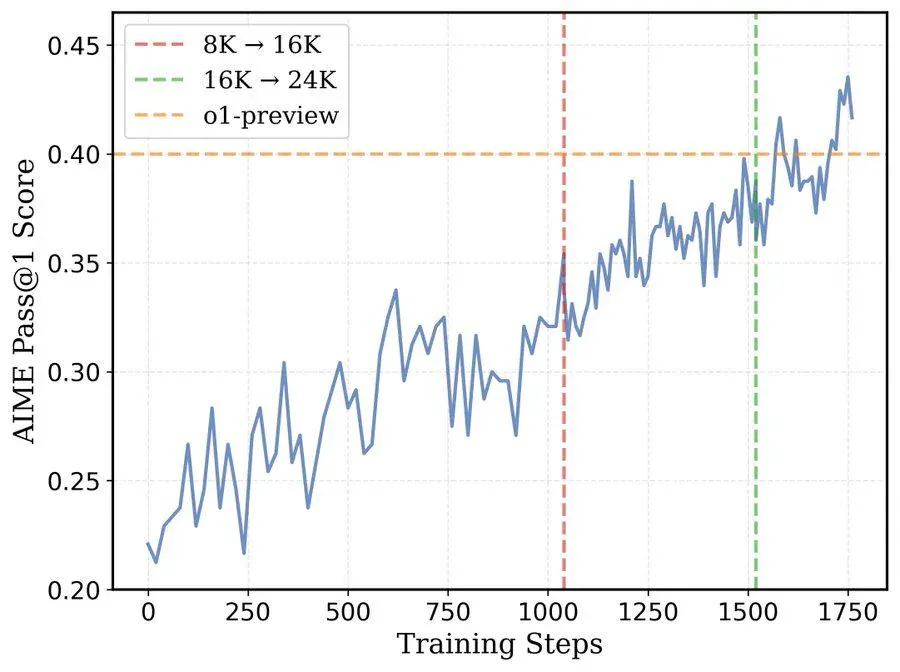
The release arrives amid growing skepticism about the AI industry’s relentless push toward ever-larger models. Where OpenAI’s o1-mini and DeepSeek’s R1 models rely on parameter counts in the hundreds of billions, DeepScaleR adopts a leaner philosophy: optimized reinforcement learning (RL), iterative training tweaks, and a laser focus on mathematical precision. Early adopters report it can solve complex math problems with 43.1% accuracy on AIME benchmarks—a 15% jump over its base architecture—while running on hardware that wouldn’t strain a university lab’s budget.
The efficiency playbook
At its core, DeepScaleR is a case study in doing more with less. Built atop DeepSeek-R1-Distilled-Qwen-1.5B, the model employs a technique called iterative context lengthening—essentially teaching the AI to “grow into” longer reasoning chains. Starting with an 8K-token context window, the system gradually expanded to 24K tokens as its accuracy improved, reducing training costs by 18x compared to conventional methods.
“It’s like teaching someone to swim in progressively deeper water,” explains Agentica’s technical documentation. “You don’t start by throwing them into the ocean.” The phased approach reportedly slashed compute requirements to just 3,800 A100 GPU hours, with a UC Berkeley team replicating the results for under $4,500.
Key to this efficiency is DeepSeek’s Group Relative Policy Optimization (GRPO), a stripped-down RL algorithm that prioritizes reward signals from the most accurate responses. Paired with a dataset of 40,000 meticulously curated problem-answer pairs from AMC, AIME, and other math competitions, the system learned to prioritize verifiable correctness over creative flourishes. Every generated solution must pass LaTeX and Sympy validation checks—a “show your work” requirement that keeps the model’s reasoning tethered to mathematical reality.
Open-source gambit in a closed-source world
What makes DeepScaleR noteworthy isn’t just its technical specs, but its licensing. By releasing training code, datasets, and experiment logs on Hugging Face and GitHub, Agentica invites scrutiny—and iteration—from a global community. It’s a direct challenge to proprietary giants like OpenAI, whose recent o3-mini release remains firmly under corporate control.
“This isn’t just about beating benchmarks,” says an Agentica researcher who asked not to be named. “It’s about proving that high-performance AI doesn’t require a trillion parameters or a Silicon Valley budget.”
The approach has skeptics. While the model excels at competition-level math problems, its real-world utility remains untested. Researchers caution that specialized benchmarks like AIME don’t reflect messy, open-ended tasks in fields like healthcare or finance—areas where larger models still dominate. There’s also the existential question hanging over all open-source AI projects: Can volunteer-driven efforts outpace the compute resources and talent pools of well-funded corporate labs?
The new smallness
For now, DeepScaleR’s implications are clearer in academia than industry. Its ability to handle 24K-token reasoning chains on consumer-grade GPUs makes it a tantalizing option for researchers exploring RL optimization or mathematical AI. And its mere existence suggests a path forward for organizations priced out of the GPU arms race.
As one MIT-affiliated engineer quipped after testing the model: “Turns out, you don’t need a sledgehammer to crack a walnut—you just need better aim.” Whether that aim holds steady against broader benchmarks—and whether the open-source community can sustain it—remains to be seen. But in an industry obsessed with scale, DeepScaleR makes a compelling case for working smarter, not bigger.