AI
A new method translates programming logic into natural language to boost problem-solving flexibility.
Large language models have become adept at narrow tasks like solving math problems or writing code snippets. But when it comes to flexible, cross-domain reasoning—connecting logical dots between scientific concepts or untangling multi-step real-world puzzles—their performance often falters. Now, researchers at Chinese AI firm DeepSeek claim they’ve found a way to bridge this gap by translating the structured logic of computer code into natural language training data.
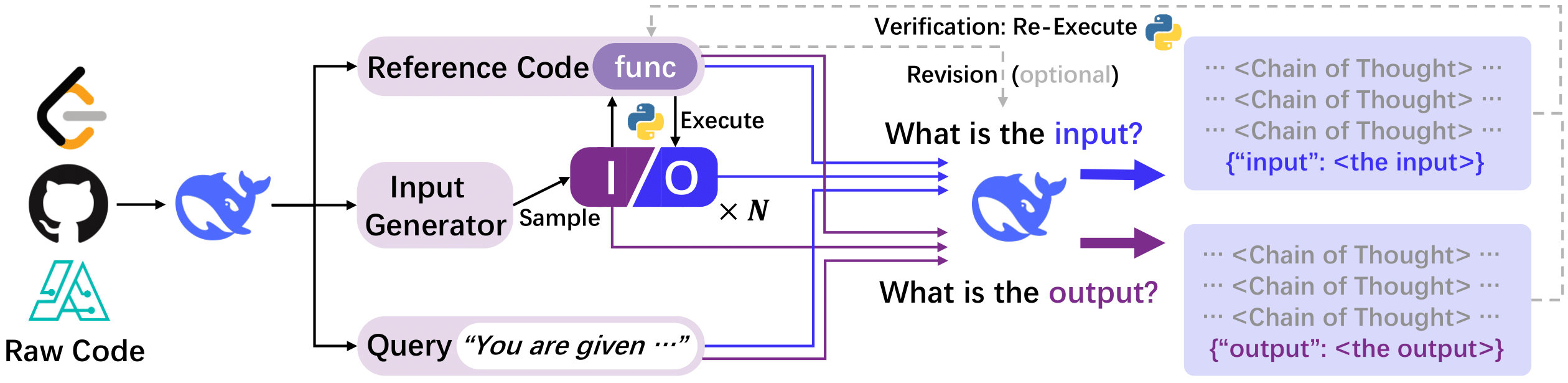
The key lies in CODEI/O, a novel framework that converts raw code into input-output prediction tasks paired with natural language explanations. Unlike traditional methods that train models directly on code syntax, this approach distills the underlying reasoning patterns—logic flow, modular decomposition, error correction—into procedural rationales any LLM can parse. Think of it as teaching the model how to think like a programmer, not just what code to write.
The code whisperer
Most attempts to sharpen AI reasoning involve either massive code-based pretraining (which embeds logic too implicitly) or rigid text-to-code generation (which traps models in syntax). CODEI/O sidesteps both by refactoring code from repositories like LeetCode and educational Python problems into executable functions. Models then learn to predict inputs or outputs using natural language chain-of-thought explanations—essentially narrating their problem-solving steps without getting bogged down in semicolons or brackets.
“It’s about decoupling the reasoning process from the programming language,” the DeepSeek paper explains. “By expressing code’s input-output relationships in natural language, we preserve procedural rigor while making the logic transferable to non-coding tasks.”
The team generated 3.5 million training samples this way. But they didn’t stop there. An enhanced variant, CODEI/O++, adds a self-revision step: when initial predictions fail, execution feedback flags errors, prompting the model to regenerate responses. This “learn from your mistakes” approach boosted accuracy in symbolic tasks by up to 12% without requiring new data—a promising sign for scalable training.
Baking in reliability
When tested on models like Qwen 2.5 7B and LLaMA 3.1 8B, CODEI/O delivered consistent gains. On the GSM8K math benchmark, performance jumped 5-10%, while logical deduction tasks like DROP saw 4-7% improvements. Crucially, unlike datasets hyper-focused on math or code (e.g., OpenMathInstruct-2), CODEI/O avoided trade-offs, lifting average scores across 14 benchmarks spanning science, commonsense QA, and algorithmic problems.
The results hint that code—often dismissed as a narrow domain—might be a Rosetta Stone for universal reasoning. By verifying predictions against actual code execution (“Does this input really produce that output?”), the method grounds abstract logic in concrete cause-effect relationships. As prior research has shown, LLMs frequently hallucinate false logical steps when relying solely on textual patterns. CODEI/O’s built-in verification acts as a reality check.
The black box cracks open a bit
This work aligns with broader efforts to demystify AI reasoning. Earlier this year, Anthropic’s neural network “dictionary learning” revealed how concepts activate across neuron clusters, while Meta’s COCONUT model explored non-verbal “latent space” reasoning. CODEI/O takes a different tack, essentially reverse-engineering code’s problem-solving heuristics into language any LLM can adopt.
But challenges remain. While the method improves performance, it doesn’t yet approach human-level robustness—a single irrelevant detail can still derail models, as Apple’s red herring tests demonstrated. And scaling to more complex reasoning (think graduate-level proofs or real-time scientific modeling) will require richer code sources than current datasets provide.
For now, DeepSeek has open-sourced the framework, inviting others to build on it. As one researcher noted, combining CODEI/O with inference-time techniques like reinforcement learning could be the next step. After all, if code holds the keys to logical reasoning, we’re just starting to map the locks it can open.