AI
If you've spent time on AI music platforms like Suno or Udio, you’ve likely noticed their Achilles’ heel: Most struggle to generate tracks longer than two minutes without losing coherence. That limitation may soon feel quaint. A new open-source model called DiffRhythm promises to generate 4 minute 45 second stereo tracks at CD quality—lyrics, vocals, and instrumentation—in just 10 seconds on consumer-grade GPUs, according to research published last week.
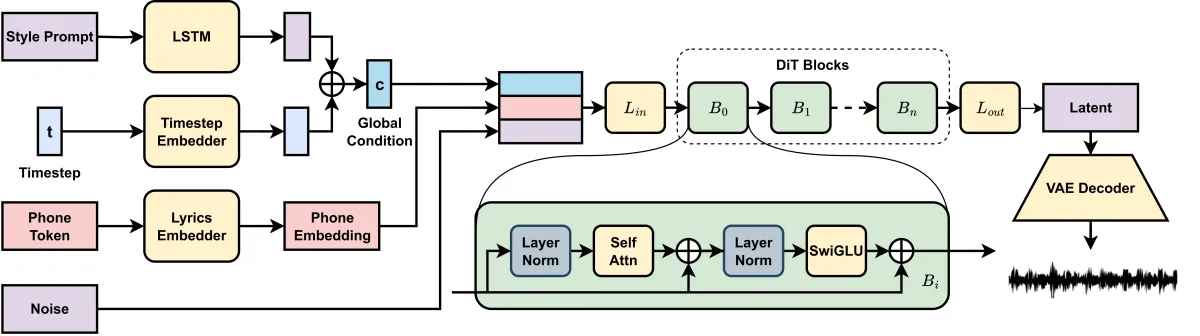
Developed by researchers at Northwestern Polytechnical University and CUHK-Shenzhen, the system leverages latent diffusion—the same technology powering image generators like Stable Diffusion—to create a compressed “blueprint” of audio. This approach, detailed in a paper and accompanying GitHub repository, avoids the computational nightmare of modeling raw waveforms directly. Instead, it trains a variational autoencoder (VAE) to convert audio into a compact latent space 2,048 times smaller than the original signal. A diffusion transformer then generates these latent representations from text prompts and lyrics before decoding them back into full songs at 44.1 kHz.
The result? A system that outpaced existing models by 50x in speed during benchmarking while maintaining “high musicality and intelligibility,” according to the team. Early examples showcase surprisingly clear vocals synced to instrumentals across genres from pop ballads to electronic dance tracks. But like most AI-generated music today, the outputs walk a tightrope between competence and Uncanny Valley: One moment you’re nodding along to a catchy melody; the next, disjointed lyrics or an abrupt key change snap you back to reality.
Brief latency, lasting questions
DiffRhythm’s architecture sidesteps many pitfalls plaguing earlier AI music tools. By using a non-autoregressive model (which generates all parts of a song simultaneously rather than sequentially), it avoids the compounding errors and glacial speeds of language model-based systems like Google’s MusicLM. The VAE’s ability to restore MP3-compressed audio also lets it train on lower-quality sources without sacrificing output fidelity—a critical advantage given how much of the world’s music catalog exists solely in lossy formats.
Perhaps most intriguing is its sentence-level alignment system, which maps phonemes to specific timestamps in the latent space using grapheme-to-phoneme conversion. Unlike traditional text-to-speech models requiring frame-perfect annotations, this method only needs approximate sentence-start markers, making it easier to synchronize lyrics with vocals across five-minute tracks. Project demos show the system maintaining lyrical intelligibility even when accompaniment drowns out parts of the vocal—a common challenge in music mixing.
Not everyone’s convinced this AI's generated music has found its rhythm. A Hacker News discussion reacting to DiffRhythm samples highlighted persistent gaps between artificial and human composition. Users noted the generated tracks often lack traditional song structure—no choruses, verses, or dynamic shifts—resulting in “glitchy lyrics over a bland backing track,” as one commenter put it. Others compared early outputs to elevator music: technically competent but devoid of narrative arc or emotional contour.
For now, the tech’s greatest impact might be reframing what’s possible. Much like MIDI and samplers birthed entirely new genres, tools like DiffRhythm could democratize music creation while challenging our definitions of artistry.