AI
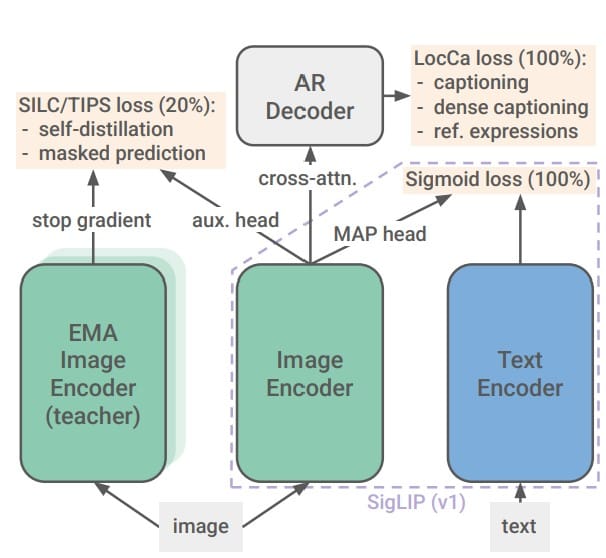
When Google researchers first introduced SigLIP in 2023, it reimagined vision-language training by replacing CLIP’s contrastive learning with a simpler binary classification approach. Now, the team is back with SigLIP 2—a family of open models that pushes multimodal AI forward through architectural tweaks, smarter training strategies, and a stronger focus on global accessibility. Released via Hugging Face and Google’s Big Vision framework, these models aim to address some of the most persistent limitations in visual-language understanding.
The multilingual pivot
While most vision-language models excel with English-centric tasks, SigLIP 2 takes a deliberate turn toward global utility. The system trains on WebLI—a sprawling dataset of 10B images and 12B text snippets spanning 109 languages. But there’s a twist: instead of equal language distribution, researchers used a 90:10 split favoring English content. This hybrid approach, validated in earlier work, aims to preserve English performance while boosting multilingual capabilities.
The results? On the Crossmodal-3600 benchmark, SigLIP 2’s image-text retrieval accuracy jumped 7-9% for low-resource languages like Quechua and Bhojpuri compared to its predecessor. Even in script-heavy tasks like Arabic document understanding, the L-sized model achieved 78.8% recall@1—a 15-point leap over vanilla SigLIP.
Seeing the whole picture (without distortion)
One of the quiet revolutions in SigLIP 2 is its NaFlex variant—a nod to Google’s earlier NaViT and FlexiViT projects. By processing images at their native aspect ratios through dynamic patch grids, NaFlex eliminates the squishing artifacts that plague standard square-input models. This proves particularly valuable for:
- Document analysis: 14% better accuracy on HierText benchmarks
- Geographic diversity: 8% higher zero-shot accuracy on the Dollar Street dataset for low-income imagery
- Medical imaging: Preserved aspect ratios in X-rays and microscopy (though clinical validation remains ongoing)
Under the hood: Training tricks that stick
The team didn’t just throw more data at the problem. Three key technical upgrades drive SigLIP 2’s gains:
-
Caption-driven pretraining: Borrowing from LocCa, researchers added a transformer decoder that generates captions while learning spatial relationships. This boosted referring expression accuracy by 18% on RefCOCO benchmarks.
-
Self-supervised double play: During the final 20% of training, models simultaneously learn through:
- Global-local consistency: Matching partial image views to full-scene embeddings
- Masked prediction: Reconstructing randomly blanked patches
-
Implicit distillation: Smaller models like ViT-B/32 get a 12% accuracy boost by learning from filtered data selected via the ACID method, which prioritizes “teachable moments” identified by a teacher model.
Benchmarks: Where it shines (and stumbles)
In zero-shot ImageNet classification, the flagship SigLIP 2 (g/16) hit 85% accuracy—a 3.8% jump over its predecessor. But the real story emerges in niche tasks:
| Task | SigLIP v1 | SigLIP 2 | Delta |
|---|---|---|---|
| COCO image→text R@1 | 76.2% | 83.1% | +6.9% |
| TextCaps retrieval | 47.2% | 55.2% | +8.0% |
| ADE20k segmentation | 37.6% mIoU | 41.8% | +4.2% |
The open-source play
Google’s decision to release four model sizes (86M to 1B params) signals a push for real-world adoption. Early experiments show:
- The So400m/14 variant runs efficiently on consumer GPUs (18ms/image on an A100)
- Fine-tuned versions already power PaliGemma’s document Q&A capabilities
- Community projects are adapting it for video understanding pipelines
Ethical guardrails
To combat dataset biases, the team implemented CLIP-style de-biasing filters that reduced gender stereotyping in occupation associations by 62%. In geolocation tasks, accuracy disparities between high- and low-income image categories narrowed from 15% to 9%.
What’s next?
As researchers experiment with SigLIP 2 in robotics and augmented reality, its true test will be handling the visual chaos of real-world applications. But by marrying architectural flexibility with smarter training—all while speaking 109 languages—this model family might just be the polyglot pivot multimodal AI needed.