AI
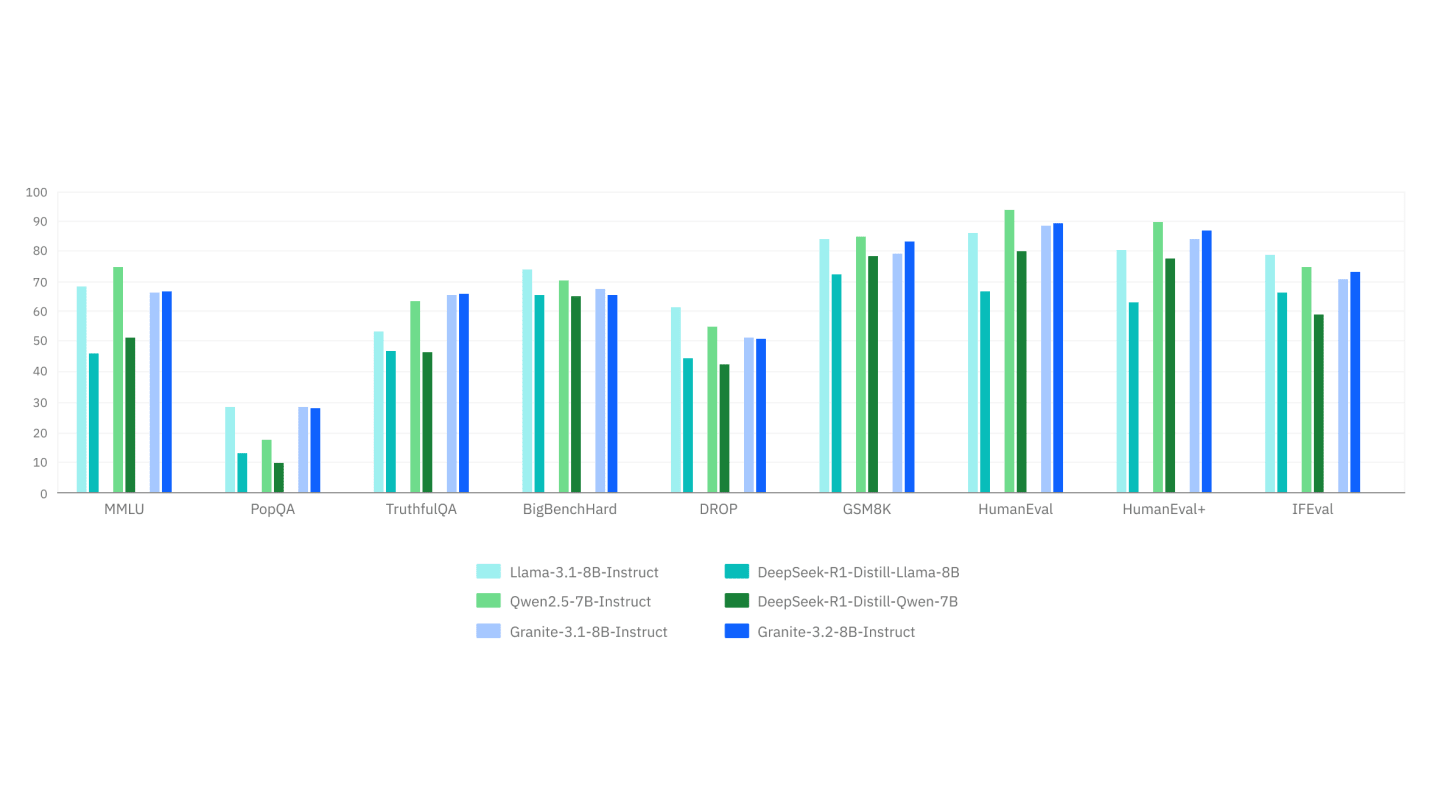
IBM has unveiled Granite 3.2, its latest open-source AI model family designed for enterprise use cases—and it’s making bold claims about performance relative to much larger systems like GPT-4o and Claude 3.5 Sonnet. The release introduces reasoning enhancements, multimodal document analysis tools, slimmer safety models, and long-term forecasting capabilities—all wrapped in Apache 2.0 licensing for commercial flexibility.
But as users quickly pointed out in discussions following the announcement, skepticism abounds around whether these compact models can truly match frontier systems or if they’re just another set of benchmark-optimized contenders in an increasingly crowded field.
Reasoning on demand (and a cloud of doubt)
At the core of Granite 3.2 are new 8B and 2B parameter instruct models featuring toggleable chain-of-thought reasoning. IBM says these can rival GPT-4o’s math skills when combined with proprietary inference scaling techniques that dynamically adjust computational effort based on task complexity. The approach allows developers to switch reasoning workflows on or off via a simple API parameter—a pragmatic touch for cost-conscious enterprises.
But benchmarks tell only part of the story:
- In IBM’s internal tests using AIME2024 (math competition problems) and MATH500 datasets, Granite 3.2 8B reportedly matches Claude 3.5 Sonnet when inference scaling activates multi-step deliberation.
- Independent evaluations remain scarce—a point raised repeatedly by open-source model enthusiasts who want third-party validation before trusting corporate claims.
Vision built for boardrooms (not vacation photos)
While most vision-language models prioritize natural images, Granite Vision 3.2 targets document understanding—flowcharts, financial reports, technical diagrams—with a twist:
- Trained on 85 million PDFs processed via IBM’s open-source Docling toolkit
- Augmented by 26 million synthetic Q&A pairs mimicking real-world enterprise queries
- Outperforms larger rivals like Llama 3.2 11B on DocVQA and ChartQA benchmarks
Guardrails get leaner (and chattier)
Granite Guardian 3.2 introduces two smaller safety variants:
- A 5B model via layer pruning (30% lighter than prior versions)
- A 3B-A800M Mixture-of-Experts variant activating only 800M params per query
Both feature verbalized confidence scoring—graded assessments like “high risk (78% confidence)” instead of binary flags—to help developers calibrate trust thresholds.
IBM claims these maintain 3.1-era detection accuracy while cutting inference costs by up to 40%. But users familiar with earlier Granite iterations remain wary: “Verbalized ambiguity sounds good until you need deterministic filtering,” noted one Redditor working on compliance systems.
Open source meets enterprise pragmatism
All Granite 3.x models are Apache 2.0 licensed, available via:
- Hugging Face (8B Instruct)
- LM Studio
- Ollama (community ports pending)
- Watsonx.ai for enterprise deployments
This openness contrasts with proprietary competitors but highlights a growing industry tension: As multiple vendors flood the market with free small models (see: Microsoft’s Phi-3-vision), differentiation increasingly depends on specialized training data and tooling rather than raw architecture.
The takeaway: Wait for real-world stress tests
IBM’s pitch—efficient reasoning tuned for business workflows resonates theoretically but faces practical hurdles:
- Enterprise adoption requires seamless integration with legacy systems far beyond what GitHub demos show
- Performance claims need independent vetting against real corporate data
- Safety tooling must evolve faster than adversarial prompt engineering