AI
For years, the AI world has operated under one fundamental assumption: that large language models must predict text sequentially, word by word, to achieve human-like capabilities. A groundbreaking new study challenges that paradigm through an unlikely contender – a diffusion model called LLaDA that generates text through iterative refinement rather than linear prediction. The implications could reshape everything from how we design AI systems to how we conceptualize machine reasoning.
Breaking the autoregressive mold
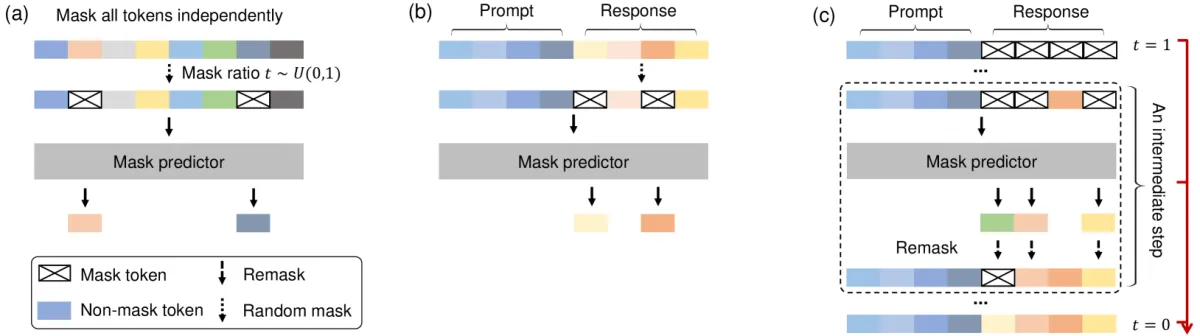
Traditional LLMs like ChatGPT and Gemini use autoregressive architectures that generate text left-to-right, constantly asking "What word comes next?" While effective, this approach creates computational bottlenecks and struggles with bidirectional reasoning. LLaDA takes inspiration from image generation techniques, starting with fully masked text and progressively revealing words through a denoising process – like watching an AI develop its thoughts through multiple drafts rather than streaming them in real time.
The system trains on 2.3 trillion tokens using a novel masking strategy where portions of text are randomly obscured during training. A vanilla Transformer then learns to predict missing words at different noise levels, optimizing what the researchers call a "principled generative approach" that models entire sequences simultaneously. This architecture allows LLaDA to consider context from all directions – a radical departure from the tunnel vision of traditional LLMs.
When scaled to 8 billion parameters, LLaDA matches or surpasses Meta's LLaMA3 8B on multiple benchmarks including MMLU for language understanding and GSM8K for mathematical reasoning. In one striking demonstration, it solved a multi-step word problem about weekly clip sales by iteratively refining numerical calculations – all without the step-by-step token prediction used by conventional models.
Perhaps most impressively, LLaDA appears immune to the "reversal curse" that plagues current LLMs. Where GPT-4o struggles to complete reversed lines of poetry while acing forward versions, LLaDA showed nearly identical performance in both directions. The researchers attribute this to the model's non-directional training approach, which treats text as a cohesive structure rather than a linear sequence.
While promising, LLaDA's architecture introduces new challenges. The diffusion process requires multiple denoising steps (typically 10-20) to generate quality text, increasing computational costs compared to single-pass autoregressive models. Early adopters on Hugging Face note generation speeds lag behind traditional LLMs, though the team suggests optimization techniques could close this gap.
Training stability also remains an open question. Despite using a "Warmup-Stable-Decay" learning rate schedule and other stabilization methods, the researchers acknowledge that scaling diffusion models to 100B+ parameters – now routine for autoregressive systems – will require architectural innovations.
A new frontier for AI design
The implications extend far beyond technical benchmarks. If bidirectional, non-autoregressive models can match traditional LLMs' capabilities, it could enable:
- True parallel generation: Generating entire paragraphs simultaneously rather than word-by-word
- Dynamic content editing: Modifying text at any position without regenerating subsequent content
- Enhanced reasoning: Considering problems holistically rather than through sequential approximation
For an industry obsessed with scaling parameters and token counts, LLaDA serves as a potent reminder: Sometimes breakthroughs come not from doing more of the same, but from fundamentally reimagining what's possible.