LLMs
The quest for the perfect vision backbone—a model that deftly balances accuracy, speed, and efficiency—is relentless. Enter MambaVision, a fresh hybrid architecture that fuses the best of Structured State Space Models (SSMs) and Vision Transformers (ViTs), promising to shake up the field with new state-of-the-art (SOTA) results on ImageNet-1K and beyond.
Transformers have become the Swiss Army knife of deep learning, conquering natural language, speech, and increasingly, computer vision. Their self-attention mechanism can capture long-range dependencies, crucial for understanding images. But this power comes at a cost: quadratic computational complexity with respect to input size, making training and inference expensive.
On the flip side, Mamba (Gu & Dao, 2023) introduced a novel SSM with linear time complexity, a clever selective scanning mechanism that shines in long sequences for language tasks. However, Mamba’s autoregressive, step-by-step processing fits sequence data well but struggles with images. Unlike text, pixels don’t have a strict ordering; spatial relationships are local and parallel. Pure Mamba models can’t fully leverage global context efficiently, limiting accuracy in vision tasks.
MambaVision’s authors took a systematic approach: redesign the Mamba block for vision, then blend it with Transformer blocks in a hybrid architecture. Their insight? Placing several self-attention layers at the tail end of the network stages greatly improves global context capture without sacrificing throughput.
The macro architecture is hierarchical:
- Early stages: CNN-based residual blocks rapidly extract features from high-resolution inputs.
- Later stages: Redesigned MambaVision mixers and Transformer self-attention blocks process lower-resolution embeddings to capture fine-grained and long-range dependencies.
This design contrasts with earlier Mamba-based backbones that either stuck to uniform blocks or used bidirectional SSMs. MambaVision cleverly assigns CNNs to handle the heavy lifting upfront and uses SSM and attention where they excel most.
At the core of MambaVision is a revamped mixer block. The original Mamba uses a causal convolution within its SSM branch—this temporal directionality makes sense for sequences but is unnecessarily restrictive for images. MambaVision replaces this with a regular convolution, allowing the model to consider information from all directions.
But it doesn’t stop there. To compensate for any information lost by the sequential component, they add a symmetric branch without SSM, consisting of a convolution followed by a SiLU activation. The outputs of both branches are concatenated and linearly projected, yielding a richer representation that captures both spatial and sequential cues.
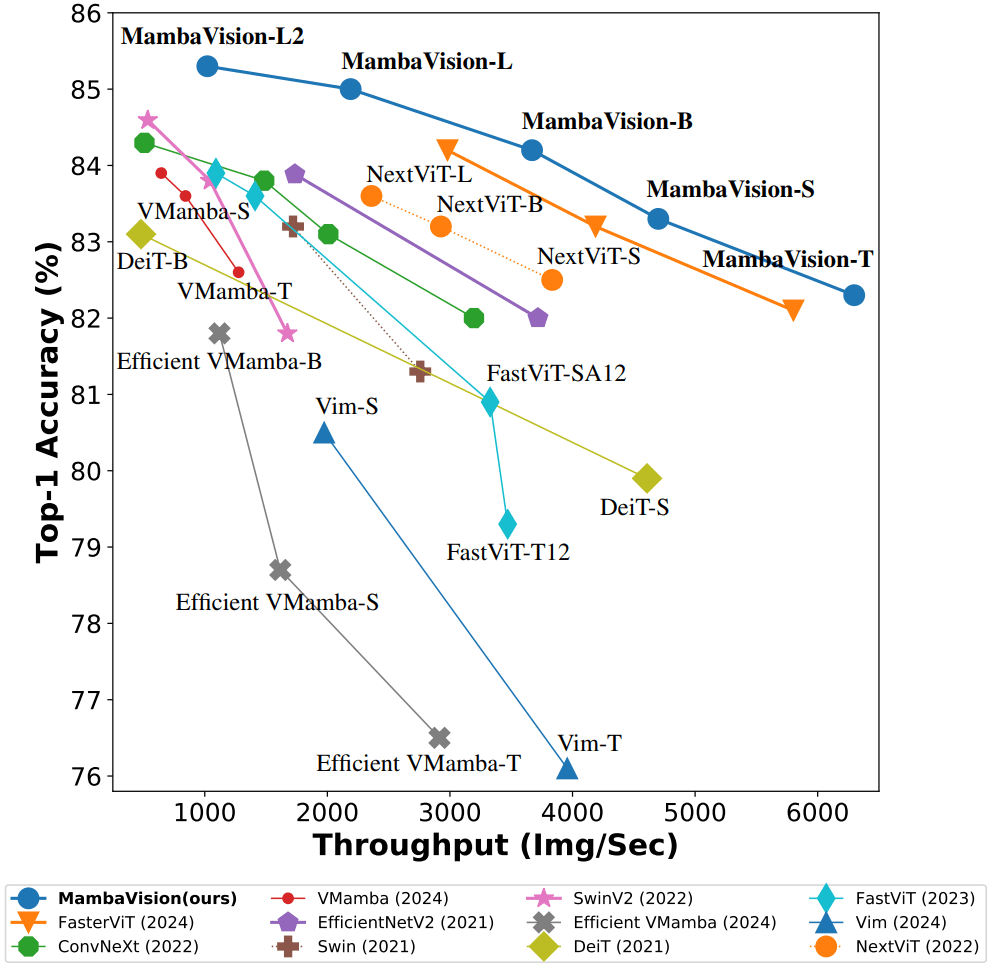
On the classic ImageNet-1K classification benchmark, MambaVision models set a new Pareto frontier by simultaneously achieving higher top-1 accuracy and better image throughput than the competition.
Take the MambaVision-B variant:
- Top-1 Accuracy: 84.2%, edging out ConvNeXt-B (83.8%) and Swin-B (83.5%)
- Throughput: Significantly higher than both ConvNeXt and Swin Transformers at similar sizes
- FLOPs: Lower than many similarly sized models, including the heavy-hitter MaxViT-B
In downstream tasks, MambaVision continues to impress:
- Object Detection & Instance Segmentation (MS COCO): Using a simple Mask R-CNN head, MambaVision-T outperforms ConvNeXt-T and Swin-T in box and mask AP. Larger MambaVision variants maintain the lead across Cascade Mask R-CNN setups.
- Semantic Segmentation (ADE20K): With a UPerNet head, MambaVision-T/S/B models surpass their Swin counterparts by margins of 0.6 to 1.0 mIoU points.
The code is open source at NVlabs/MambaVision, inviting the community to explore this promising direction.
While the Transformer revolution in vision is far from over, MambaVision opens a new chapter showing that state space models and self-attention can coexist—and complement each other—to build faster, smarter vision backbones. It will be exciting to see how this hybrid approach evolves and whether it will inspire further innovations bridging sequence modeling and vision.
For readers hungry for technical depth, the full arXiv paper MambaVision: A Hybrid Mamba-Transformer Vision Backbone details the architecture, experiments, and ablations with mathematical rigor and practical insights.