LLMs
Large Language Models (LLMs) have become the darlings of AI, powering everything from chatbots to code generation. But with great scale comes great cost: training and running models with billions of parameters gobble up vast computational resources, memory, and energy, making them inaccessible for many and environmentally taxing. Enter Microsoft’s BitNet b1.58 2B4T, an open-source 2-billion-parameter LLM trained on a staggering 4 trillion tokens, which boldly challenges the notion that bigger and more precise is always better.
At 2 billion parameters, BitNet b1.58 sits in the small-to-mid-size LLM category, roughly comparable to models like Phi-2 or smaller variants of LLaMA. But it’s the training dataset size that truly stands out: 4 trillion tokens — a volume rivaling or exceeding that used by much larger models. Why train a relatively small model on such an enormous corpus?
The result, as detailed in Microsoft’s technical report and blog coverage, is a model that reportedly matches or even surpasses some larger full-precision models on a variety of benchmarks, including language understanding, reasoning, math, and code generation.
BitNet b1.58 shines in several ways:
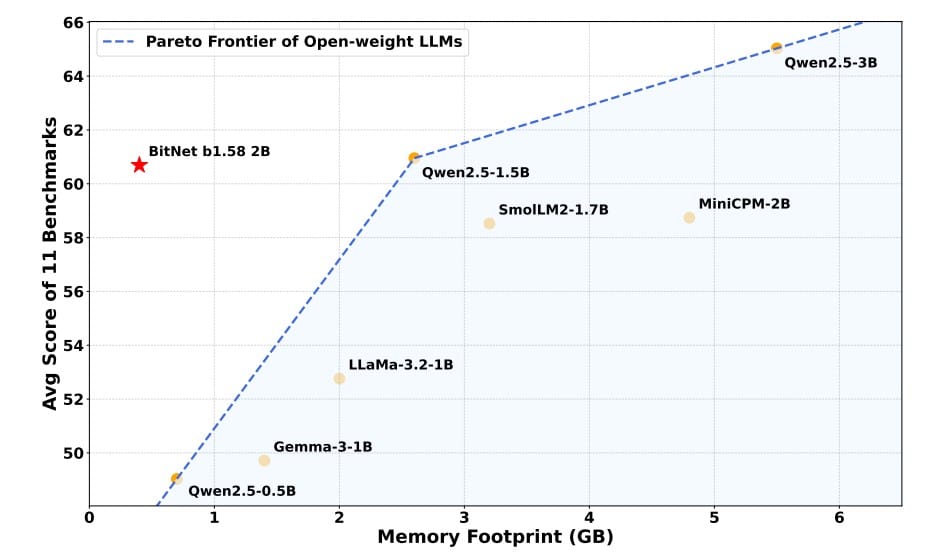
- Memory footprint: At just 0.4 GB of non-embedding memory during inference, it uses roughly 8–10x less memory than comparable 16-bit models.
- Latency and energy: On CPUs, inference latency clocks in at about 29 ms per token, with an estimated energy consumption of only 0.028 joules — a fraction of what typical LLMs need.
- Benchmark results: Across diverse benchmarks like ARC Challenge, BoolQ, PIQA, and GSM8K, BitNet performs competitively, often outperforming other open-weight full-precision models of similar or larger size.
For example, on the ARC Challenge (a difficult reasoning benchmark), it achieves ~50% accuracy, beating several larger models that hover in the 30–40% range. On GSM8K (math problems), it hits nearly 58% accuracy, outperforming many full-precision peers.
A side-by-side comparison with popular models shows BitNet offering a compelling efficiency-performance sweet spot, often surpassing post-training quantized (PTQ) competitors that apply INT4 quantization on full-precision models. Unlike PTQ methods that often degrade model quality, BitNet’s native 1-bit training preserves accuracy while slashing resource usage.
BitNet b1.58 replaces standard full-precision linear layers in the Transformer with custom BitLinear layers that enforce ternary weights during forward and backward passes. Activations are quantized to 8-bit integers, further reducing computational overhead. Training incorporates:
- Sub-Layer Normalization (subln): To enhance stability in the quantized regime.
- Squared ReLU activations: Instead of the common SwiGLU, encouraging sparsity and computational efficiency.
- Rotary Position Embeddings (RoPE): For positional information.
- Bias removal: Similar to LLaMA, to simplify quantization.
The training proceeds in three phases: large-scale pretraining on the 4T token dataset, supervised fine-tuning on instruction-following and conversational datasets, and Direct Preference Optimization (DPO) to align outputs with human preferences without the complexity of reinforcement learning.
A model this aggressively quantized requires specialized inference implementations:
- GPU: Microsoft developed a custom CUDA kernel to handle the ternary weights packed efficiently in memory and perform fast matrix multiplications with 8-bit activations. However, current GPUs—optimized mainly for floating-point and INT8—aren’t ideal for such 1-bit operations, leaving room for future hardware co-design.
- CPU: The open-source bitnet.cpp library offers optimized CPU inference, enabling deployment on laptops and edge devices without GPUs.
While BitNet b1.58 2B4T is a landmark proof-of-concept, many open questions remain:
- Scaling laws: How will native 1-bit models perform at larger scales (7B, 13B parameters and beyond)?
- Long-context handling: Extending sequence length to tackle tasks needing broader context.
- Multilingual and multimodal: Currently English-focused, future versions might integrate other languages and modalities like images.
- Hardware innovation: Co-design of ASICs or FPGAs optimized for low-bit operations could unlock massive efficiency gains.
- Fine-tuning and usability: Understanding how well these models adapt to downstream tasks and real-world applications.
Microsoft’s open-source release invites the community to explore these directions and build upon what could be the foundation for a more sustainable and accessible AI future.
In a world obsessed with ever-larger, more precise models, BitNet b1.58 2B4T is a refreshing reminder that less can be more.