AI
A new tool from Microsoft aims to give AI models better “eyes” for navigating the messy world of graphical interfaces—without peeking under the hood.
Released this week on Hugging Face and GitHub, OmniParser V2 converts screenshots of apps or websites into structured data that AI agents can parse. The system combines object detection, image captioning, and optical character recognition (OCR) to map out clickable elements like buttons and text fields. For vision-language models (VLMs) such as GPT-4V, it’s like swapping foggy glasses for high-def lenses: Early benchmarks show the tool boosting GPT-4V’s accuracy by up to 73% on interface interaction tasks.
Seeing through the noise
Modern interfaces are minefields for AI. Buttons hide behind inconsistent icons. Menus morph across platforms. Dropdowns defy spatial logic. OmniParser tackles this chaos with a one-two punch: A YOLOv8 model finetuned to spot interactable regions, paired with a BLIP-2 or Florence-2 component that labels each element’s purpose. An OCR module overlays text onto this map, creating a blueprint that tells AI agents where to click and why.
The magic lies in the training data—a curated mix of website screenshots annotated using DOM trees, which helps the system generalize across desktop, mobile, and web interfaces. Unlike Apple’s Ferret-UI (tailored for iOS) or Anthropic’s closed “Computer Use” feature, Microsoft’s approach doesn’t rely on platform-specific metadata. It’s screen scraping, upgraded.
Benchmarks and tradeoffs
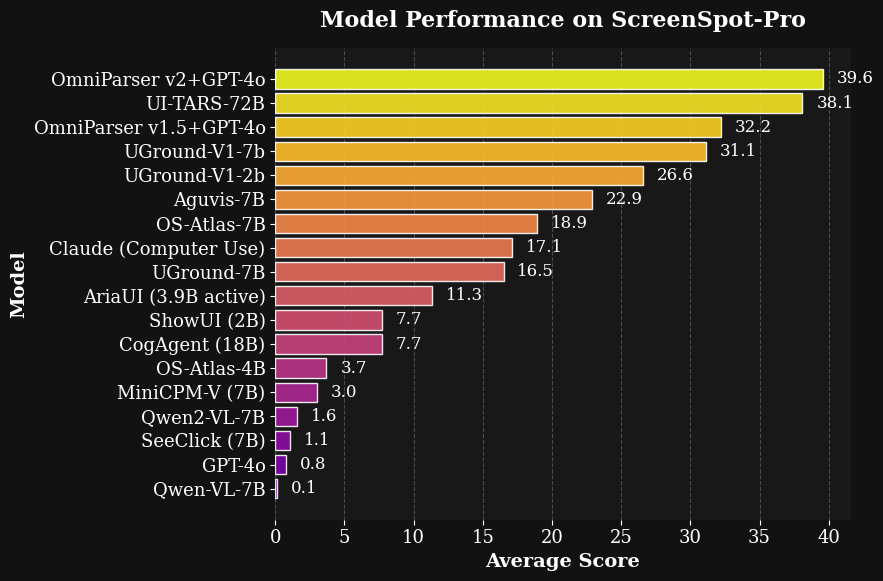
In tests on the ScreenSpot benchmark, OmniParser V2 reportedly boosted GPT-4V’s accuracy from 70.5% to 93.8% for icon recognition. It also outperformed raw GPT-4V on the Mind2Web and AITW benchmarks using only pixel data—no HTML or accessibility tags. Microsoft claims the V2 update slashes latency by 60% compared to its predecessor while scoring 39.6 on the tougher ScreenSpot Pro evaluation.
But the system isn’t flawless. Like a distracted intern, it sometimes misaligns text boxes or confuses duplicate buttons. Microsoft acknowledges these hiccups in the model card, noting challenges with “repeated UI elements” and OCR drift. The team is banking on open-source contributions to refine accuracy, positioning OmniParser as a community-driven alternative to walled gardens like Google’s Project Mariner.
The vision-only gamble
Security hawks might breathe easier here. By avoiding direct DOM or API access—methods that could expose sensitive data—OmniParser’s screenshot analysis sidesteps some risks of tools that take over your mouse. Early adopters are already plugging it into workflow automators and accessibility tools, with some developers hailing its compatibility with smaller models like Phi-3.5-V.
Yet the broader question lingers: Can pixel parsing ever match the precision of direct system access? For now, Microsoft bets the answer is “good enough”—and with AI agents poised to handle everything from tax forms to cross-app workflows, “good enough” might just unlock a new era of ambient computing. Provided the AI doesn’t keep clicking the wrong submit button.