AI
Edited Feb 16, 2025
Hugging Face-led collaboration proves smaller models can punch above their weight with specialized training.
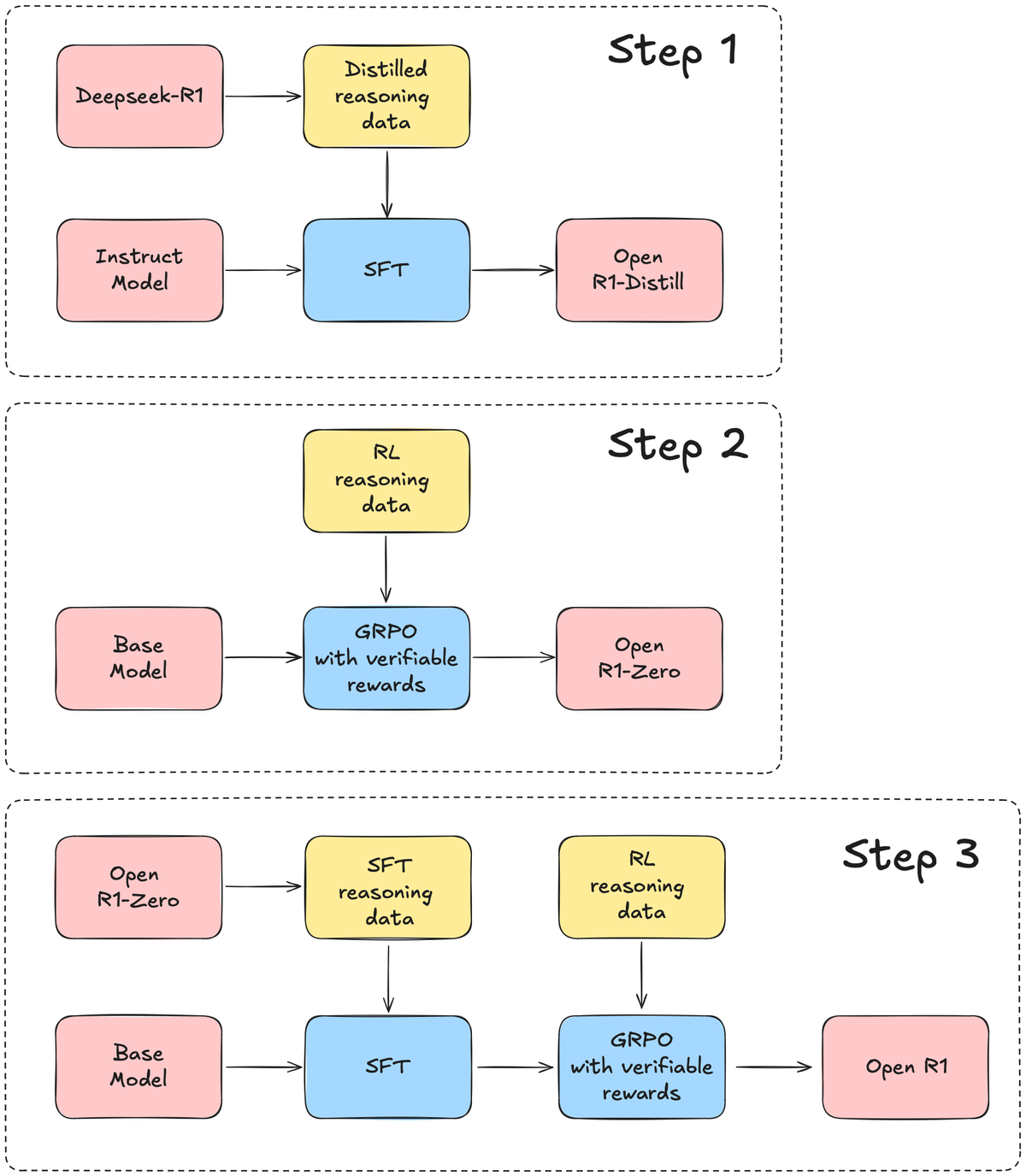
A coalition of AI researchers has pulled back the curtain on OpenR1-Qwen-7B—an open-weights language model that replicates the mathematical prowess of China’s cutting-edge DeepSeek-R1 through collaborative engineering. The project demonstrates how focused fine-tuning and synthetic data can give smaller models outsized capabilities, achieving parity with their larger counterparts in specialized domains.
Built on Alibaba’s Qwen-7B architecture, the model underwent rigorous training using 220,000 human-verified math solutions generated by DeepSeek’s original R1 system. The process required meticulous optimization of "chain-of-thought" reasoning traces—the step-by-step logic AI uses to solve problems—while balancing computational costs that ran up to 15 solution attempts per hour on high-end H100 GPUs.
When less becomes more
Early benchmarks tell a compelling story: OpenR1-Qwen-7B matches its DeepSeek-R1-Distill-Qwen-7B progenitor’s 94.3 percent accuracy on the MATH-500 assessment while showing competitive performance in coding challenges. This parity comes despite using conventional supervised learning rather than the reinforcement learning approaches that typically require massive compute resources.
The secret sauce? Knowledge distillation—a technique where smaller models learn directly from the outputs of larger ones.
From research labs to laptops
Practical implementation gets clever with quantization—compressing the model through techniques like GGUF formatting to run efficiently on consumer-grade hardware. Early adopters report the system operates smoothly on Apple Silicon chips and mid-tier NVIDIA GPUs, bypassing the need for expensive cloud compute.
The project’s GitHub repository goes beyond mere code dumps, offering full training recipes and alignment techniques. Early tests suggest these implementations deliver responses 1.74× faster than comparable dense models while maintaining accuracy.
The open source endgame
This release continues Hugging Face’s pattern of rapid-response cloning—a strategy previously seen when the company recreated OpenAI’s Deep Research agent in under 24 hours.
As the team notes in their technical deep dive, future plans include expanding to chemistry and physics domains—proving that in the AI arms race, sometimes the most interesting developments come from sharing rather than hoarding.