Circavoyant
Lighting the fuse on tech topics that haven't exploded—yet.


Read Our Latest Posts
Latest Posts
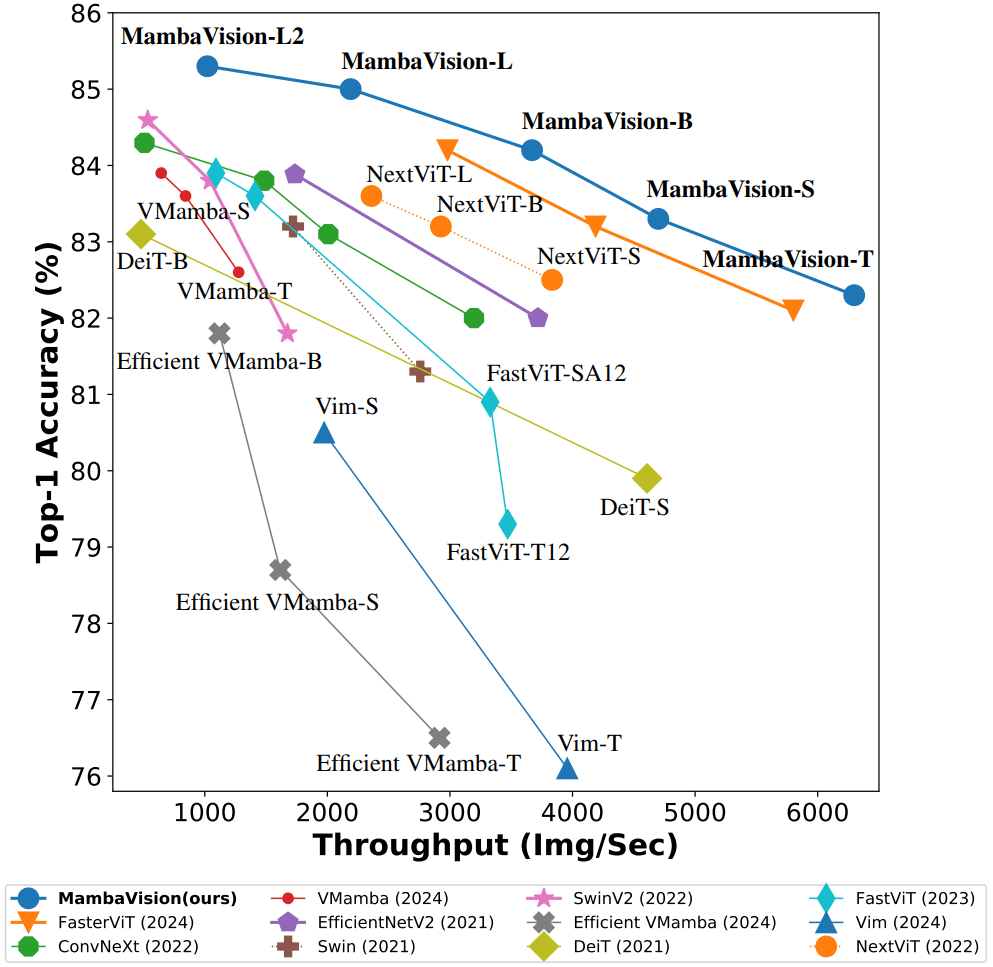
The quest for the perfect vision backbone—a model that deftly balances accuracy, speed, and efficiency—is relentless. Enter MambaVision, a fresh hybrid architecture that fuses the best of Structured State Space Models (SSMs) and Vision Transformers (ViTs), promising to shake up the field with new state-of-the-art (SOTA) results on
Text-to-speech (TTS) technology has long been a staple of virtual assistants, accessibility tools, and interactive systems. But the latest player on the scene, Sesame CSM-1B, isn’t just turning text into robotic-sounding speech—it’s aiming to elevate speech synthesis into the realm of natural, context-aware conversations. Built atop the
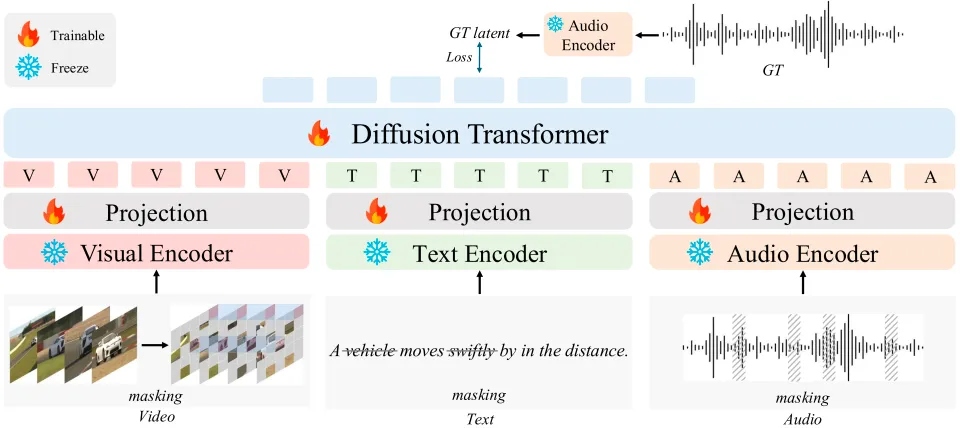
Audio generation and music synthesis have been hotbeds of AI innovation lately, but the field has often been siloed. You get a model specialized in text-to-audio, another in video-to-audio, and yet another churning out music — each excelling in their own corner but unable to talk to each other or handle

If you’ve ever found yourself drowning in a sea of bookmarks, scattered notes, and random screenshots while trying to recall that one article or tutorial you swore you saved, SurfSense might just be the lifebuoy you’ve been waiting for. Positioned as a hybrid between Google’s NotebookLM and

If you thought the AI arms race was all about bigger models and more parameters, think again. The latest battleground for advancing artificial reasoning isn’t just in neural net architecture—it’s in the data itself. Hugging Face, Bespoke Labs, and Together.ai have teamed up to kick off

The era of large-scale AI training dominated by a handful of hyperscalers might soon face a formidable challenger: a truly decentralized, permissionless platform enabling anyone with spare GPU cycles to contribute to state-of-the-art AI development. Enter Prime Intellect’s INTELLECT-2, a 32-billion-parameter reinforcement learning (RL) training run that’s not
Running cutting-edge large language models (LLMs) like Llama 3 or DeepSeek R1 locally has long been a pipe dream for most users. The resource demands—massive GPU clusters, copious RAM/VRAM, and lightning-fast network links—have kept these frontier AIs shackled to the cloud. But what if you could unleash

In the rapidly evolving landscape of multimodal AI, where language models are increasingly expected to see and understand images, videos, and more, InternVL3 emerges as a compelling new contender from the OpenGVLab team. Building on the InternVL series, InternVL3 introduces a fresh approach to training multimodal large language models (MLLMs)
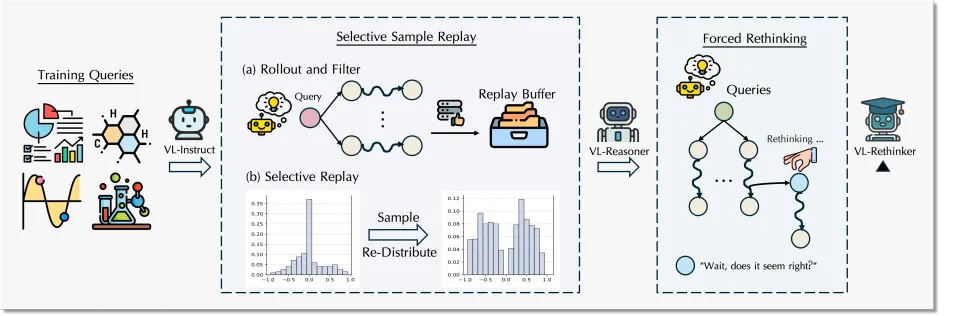
Vision-language models (VLMs) are the Swiss Army knives of AI, capable of interpreting images, videos, and text in tandem. Yet, as anyone who’s tried to get a bot to mull over a tricky problem knows, raw speed often trumps deep thought—especially when multimodal reasoning is involved. Enter VL-Rethinker,