AI
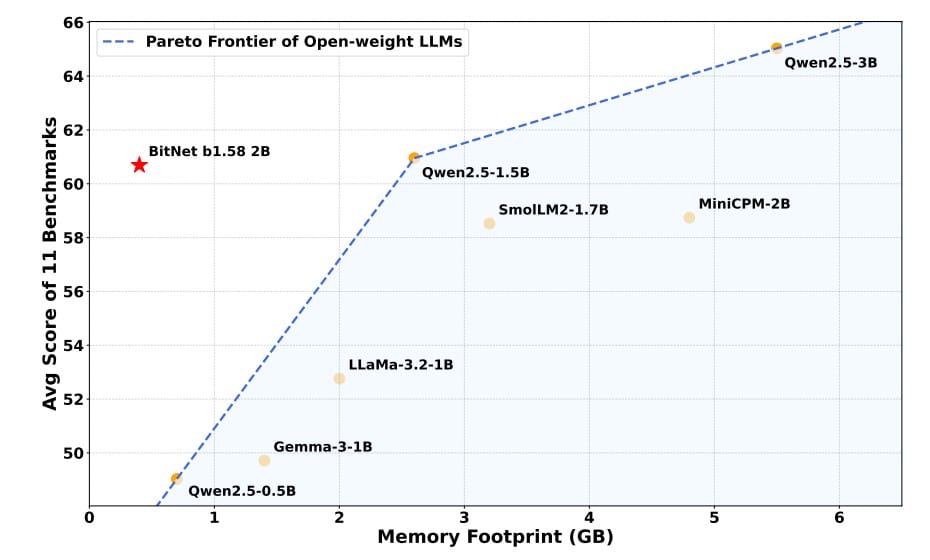
Large Language Models (LLMs) have become the darlings of AI, powering everything from chatbots to code generation. But with great scale comes great cost: training and running models with billions of parameters gobble up vast computational resources, memory, and energy, making them inaccessible for many and environmentally taxing. Enter Microsoft’
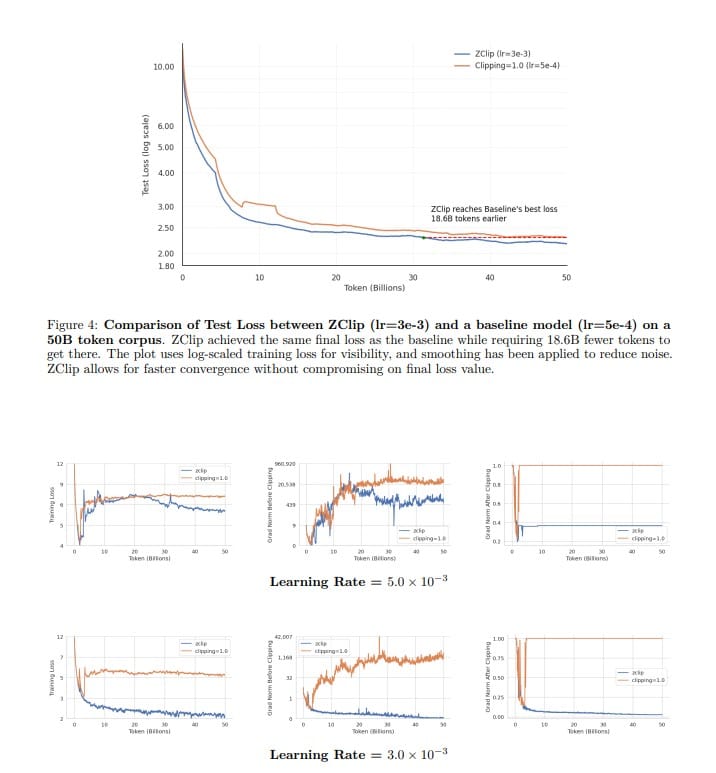
Training large language models (LLMs) is a bit like herding caffeinated cats: the gradients can spike unpredictably, causing loss functions to go haywire and sometimes leading to catastrophic divergence that forces you to restore checkpoints or skip batches. Traditional gradient clipping methods—those trusty fixed-threshold or norm-based hacks—often fall
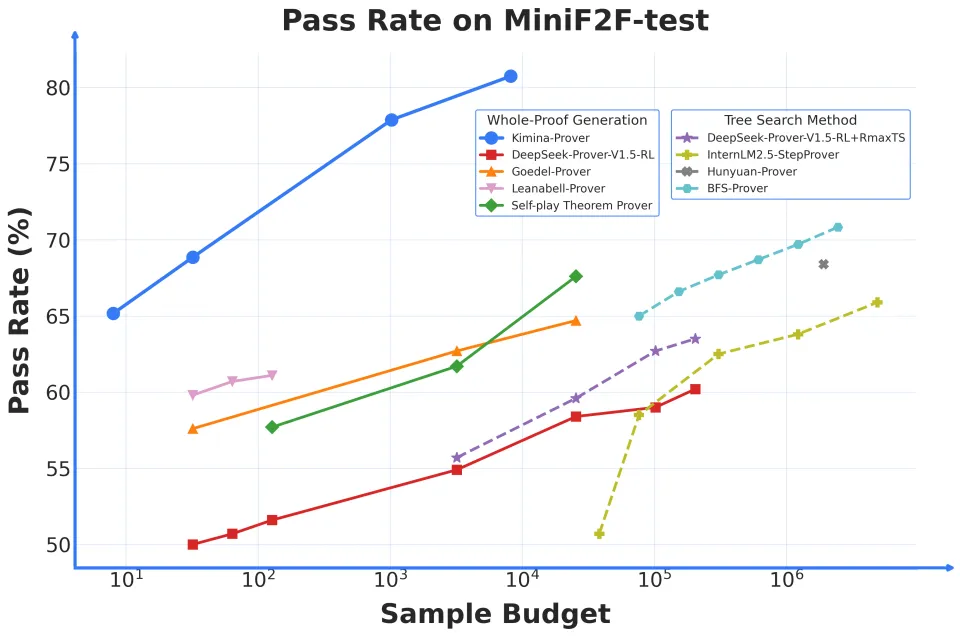
Mathematical theorem proving has long been a playground for AI researchers, pushing the boundaries of formal reasoning and symbolic logic. Today, a fresh contender named Kimina-Prover Preview, developed by the collaboration of the Moonshot AI team (known as 月之暗面 Kimi) and Numina, has stormed the leaderboard by achieving an unprecedented

In the ever-evolving landscape of large language models (LLMs), the race isn’t just about throwing more parameters at the problem—it’s about smarter architecture and efficiency at scale. Enter Nemotron-H, a fresh family of hybrid Mamba-Transformer models that promise to deliver state-of-the-art accuracy while slashing inference costs and
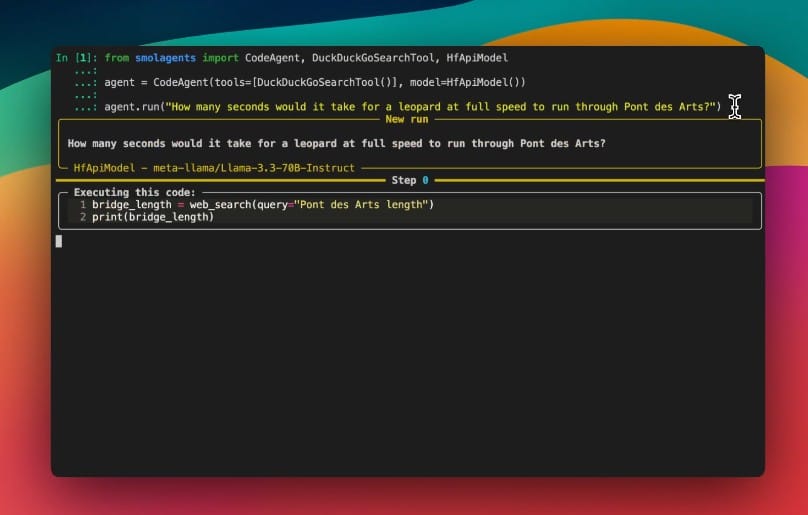
The world of large language models (LLMs) has been exploding in recent years, with innovations ranging from Meta’s LLaMA models to Huggingface’s smolagents and lightweight runtimes like llama.cpp. While OpenAI and other providers dominate with cloud-based APIs, a vibrant ecosystem has emerged around running capable models locally

Language models are the darlings of AI today, powering everything from chatbots to virtual assistants and search engines. But as anyone who’s ever been on hold with a customer service bot knows, these systems can — and do — go spectacularly wrong. While much research into AI risks has been top-down,
If you’ve ever marveled at how Character.AI manages to keep its virtual personas consistent, helpful, and engaging across millions of chats daily, you might have assumed it’s all about the underlying large language model (LLM). But as it turns out, a hefty part of the magic lies

Meta’s LLaMA series has stirred up considerable excitement among AI enthusiasts, especially with the growing ecosystem of local deployments and lightweight interfaces. But with great accessibility comes great responsibility—something that recent discussions on Reddit’s r/LocalLLaMA subreddit have highlighted in no uncertain terms. Turns out, some Ollama
OpenAI just dropped its latest AI reasoning models, o3 and o4-mini, setting the stage for a new era of "thinking" AI that can not only chat but also analyze images, run code, browse the web, and generally act more independently. But with this shiny new lineup, developers and