LLMs
Vision-language models (VLMs) are the Swiss Army knives of AI, capable of interpreting images, videos, and text in tandem. Yet, as anyone who’s tried to get a bot to mull over a tricky problem knows, raw speed often trumps deep thought—especially when multimodal reasoning is involved. Enter VL-Rethinker, a new contender in the arena that champions slow, reflective thinking baked in via reinforcement learning, and the ever-evolving Qwen2.5-VL series, Alibaba’s hefty 72-billion-parameter marvel tuned for rich visual and textual understanding. Together, they illustrate how the next wave of VLMs aims to combine the best of rapid perception with deliberate reasoning.
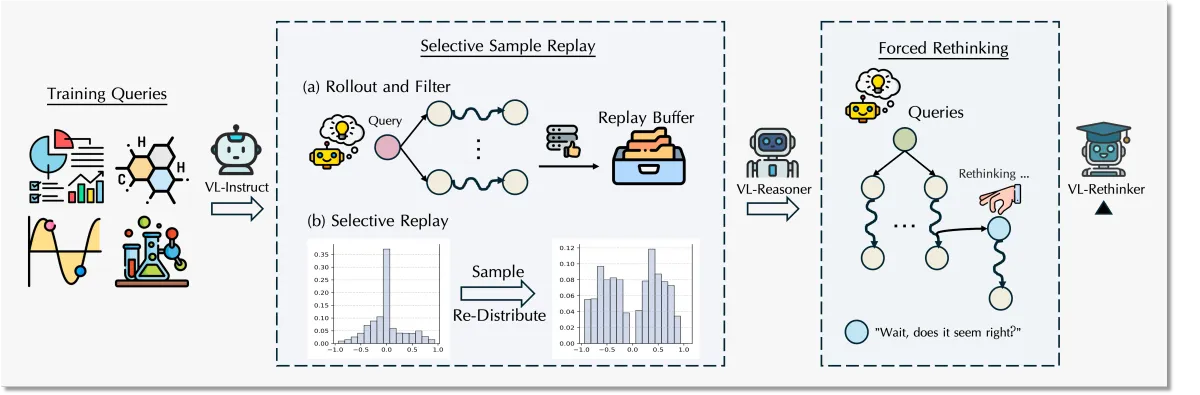
VL-Rethinker, introduced by Haozhe Wang et al. in their arXiv paper and GitHub repo, tackles this by enhancing the slow-thinking capabilities of VLMs using reinforcement learning without distillation. The core innovations are:
- Selective Sample Replay (SSR): An adaptation of the GRPO algorithm designed to fix the "vanishing advantages" problem common in reinforcement learning, where the model forgets effective strategies over time.
- Forced Rethinking: A clever trick that appends a textual "rethinking trigger" to training rollouts, explicitly encouraging the model to pause and reflect on its initial reasoning steps—a kind of AI metacognition, if you will.
The result? VL-Rethinker pushes state-of-the-art scores on benchmarks like MathVista (80.3%), MathVerse (61.8%), and MathVision (43.9%), and claims open-source leadership on multi-disciplinary challenges such as MMMU-Pro, EMMA, and MEGA-Bench, closing the gap with GPT-o1. This is a meaningful leap for VLMs, signaling that slow, reflective reasoning can be incentivized and improved with the right RL strategies.
The team has open-sourced VL-Rethinker models at 7B and 72B parameters, built atop the Qwen2.5-VL family, with 32B models underway. Their codebase also provides streamlined inference pipelines that recommend enabling flash_attention_2 for better speed and memory efficiency, especially when juggling multiple images or videos.
While VL-Rethinker focuses on the how of reflection and reasoning, the Qwen2.5-VL series embodies the what—the raw multimodal capability. Released recently by Alibaba and available on Hugging Face, Qwen2.5-VL is the latest evolution of their Qwen family, now boasting:
- Dynamic resolution and frame rate training: Allowing the model to handle images and videos of varying sizes and speeds, improving natural visual perception.
- Streamlined vision encoder: Optimized ViT architecture with window attention, SwiGLU activation, and RMSNorm to boost training and inference efficiency.
- Event pinpointing in long videos: Understanding videos over an hour long and localizing important segments.
- Agentic capabilities: Acting as a visual agent that can reason and control external tools, including phones and computers.
- Multilingual support: Beyond English and Chinese, it understands texts in European languages, Japanese, Korean, Arabic, and more.
On benchmarks, Qwen2.5-VL-72B-Instruct shows solid improvements over its predecessor Qwen2-VL and other open-source LVLMs. For example, it achieves a 74.8% on MathVista_MINI (up from 70.5%), 38.1% on MathVision_FULL (vs. 25.9%), and competitive results on video benchmarks like VideoMME with subtitles at 79.1%. In agent benchmarks, it also excels at tasks like Android control and screen spotting.
Alibaba provides detailed inference examples demonstrating how to process single or multiple images, videos (local files or URLs), and batch queries using their transformers integration combined with a handy utility library qwen-vl-utils. They also offer tips for trading off between image resolution and computational resources, plus notes on limitations like lack of audio understanding and challenges in complex spatial reasoning.
The VL-Rethinker and Qwen2.5-VL developments underscore two critical trends in vision-language modeling:
-
Incentivizing Reflection: For AI systems to tackle genuinely complex problems, especially those requiring multimodal understanding, they need to slow down and validate their reasoning. VL-Rethinker’s Forced Rethinking and SSR techniques show this is achievable through RL without resorting to distillation tricks.
-
Versatility at Scale: Models like Qwen2.5-VL are not just bigger—they’re smarter about handling diverse inputs, from static images to long-form videos and agentic interaction scenarios, making them suited to real-world applications in multimedia understanding, robotics, and beyond.
For researchers and developers looking to push the envelope of AI understanding, VL-Rethinker offers a novel training recipe that complements the raw power and flexibility of Qwen2.5-VL models. Both projects are open source, complete with training code, evaluation scripts, and pre-trained weights, fostering a more reflective and capable generation of vision-language systems.
If you’re eager to try these models yourself, the VL-Rethinker repo and Qwen2.5-VL Hugging Face pages provide comprehensive instructions and examples to get you started, whether you want to describe images, analyze videos, or benchmark on challenging reasoning tasks.