AI
Training large language models (LLMs) is a bit like herding caffeinated cats: the gradients can spike unpredictably, causing loss functions to go haywire and sometimes leading to catastrophic divergence that forces you to restore checkpoints or skip batches. Traditional gradient clipping methods—those trusty fixed-threshold or norm-based hacks—often fall short, either clipping too little or too much, and require constant babysitting by the engineer. Enter ZClip, a newly proposed adaptive gradient clipping algorithm that promises to keep training stable by dynamically tuning its thresholds on the fly.
Large language models are notorious for their unstable training dynamics. Occasionally, the gradient norms explode, resulting in sudden "loss spikes" that disrupt learning and sometimes wreck the entire training run. The usual approach is to clip gradients to a fixed maximum norm or threshold, but this static approach can be too blunt:
- Set the threshold too high, and you get wild spikes that destabilize training.
- Set it too low, and you unnecessarily hinder learning by choking gradients that are actually helping.
Neither is great, and often engineers have to tweak these parameters manually as training progresses, wasting precious time and compute.
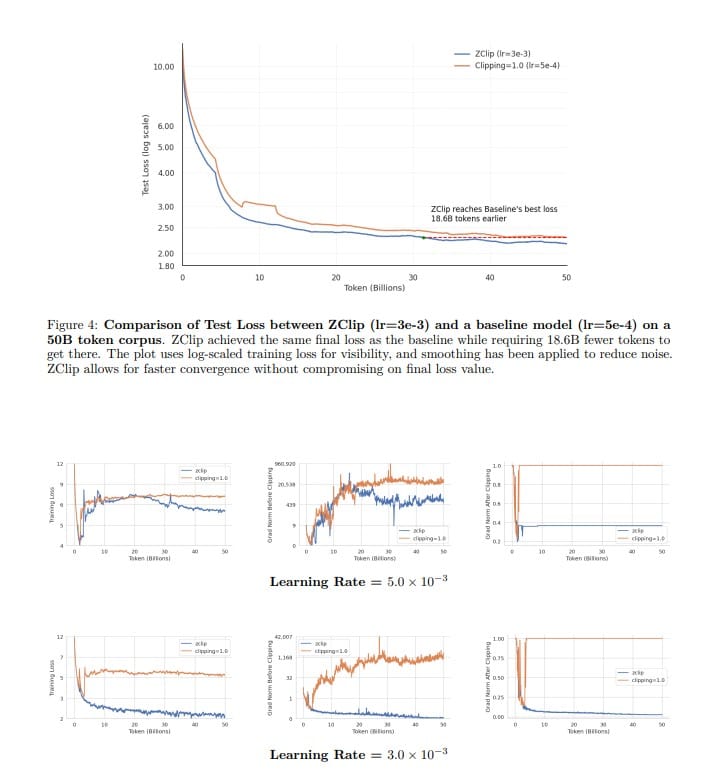
The authors of ZClip (Kumar et al., 2025) propose a clever adaptive method that treats gradient clipping more like an anomaly detection problem than a fixed rule. Instead of relying on preset thresholds, ZClip continuously monitors the statistical behavior of gradient norms during training, using an exponential moving average (EMA) to keep running estimates of the mean and variance of these norms. This lightweight running statistic lets ZClip spot when a gradient norm is a genuine outlier—a spike that deviates significantly from recent trends.
At the heart of ZClip is a z-score based clipping threshold: if the current gradient norm exceeds the EMA mean by more than a multiple of the EMA standard deviation (default z-score threshold of 2.5), ZClip clamps it down. This dynamic threshold adjusts as training progresses, adapting to the scale and volatility of gradients without human intervention.
This is a key advantage over previous methods that either use a constant clipping norm or heuristics that don’t respond well to the evolving training landscape. By acting proactively and statistically, ZClip prevents the kind of catastrophic loss spikes that can derail training, all while allowing normal convergence behavior to proceed unhindered.
ZClip is implemented as a PyTorch Lightning callback, making it easy to integrate into existing training pipelines with minimal fuss. It’s compatible with advanced distributed training setups like FSDP (Fully Sharded Data Parallel) and doesn’t require modifying core training loops beyond inserting a single .step() call after backpropagation and before the optimizer step.
The algorithm’s smoothing factor (alpha), z-score threshold (z_thresh), and clipping aggressiveness (clip_factor) are configurable knobs:
- Alpha (EMA smoothing): Controls how quickly ZClip adapts to changes in gradient distribution. Lower alpha (e.g., 0.90) makes it more sensitive to recent spikes but risks noise.
- Z_thresh: Tightening this threshold (e.g., from 2.5 to 2.0) makes clipping more aggressive, catching smaller anomalies.
- Clip_factor: Scaling this below 1.0 pushes clipping thresholds lower, which can help in highly volatile training scenarios.
These parameters allow practitioners to tailor ZClip for different models, datasets, or training regimes, especially useful when gradients are noisy or when implementing curriculum learning strategies.
As LLMs grow larger and more complex, training stability becomes ever more critical. Restarting from checkpoints or skipping batches due to loss spikes is costly in both time and compute. ZClip’s adaptive and statistically principled approach offers a promising path to smoother, more efficient training runs, reducing manual tuning headaches and potentially unlocking faster convergence.
The code is open source and available on GitHub, ready for experimentation.